Il Web
Il Web, o più pomposamente il World Wide Web, da cui si ha il famoso acronimo www, è la ragnatela mondiale che ogni giorno utilizziamo. Il Web ha riscosso talmente successo negli ultimi anni ed ha reso Internet accessibile a così tante persone da essere spesso confuso con Internet stesso. In realtà esiste una certa differenza tra Internet ed il Web: Internet è una rete di reti, ovvero è un insieme così grande di reti da coprire il mondo intero, ed è dunque l’infrastruttura su cui poggia il Web. Il Web invece è solamente una delle tante applicazioni che possono essere eseguite su Internet.
Il Web si basa sul cosiddetto modello client/server, che andremo adesso ad analizzare.
Il modello client/server
La gran parte delle applicazioni supportate da una qualsiasi rete si basa sul modello client/server. Prendiamo ad esempio un’applicazione progettata per l’accesso a file remoti. Essa è caratterizzata da una coppia di processi - in informatica un processo è un programma in esecuzione. Per semplicità supporremo che i due processi si trovino su due macchine distinte, uno che richiede l’accesso in lettura o in scrittura al file remoto, l’altro che onora tale richiesta. Il processo che richiede accesso al file è chiamato client, termine con il quale si identifica solitamente anche il PC su cui viene eseguito tale processo. Invece, il processo che fornisce accesso al file viene denominato server, così come la macchina su cui tale processo viene eseguito.
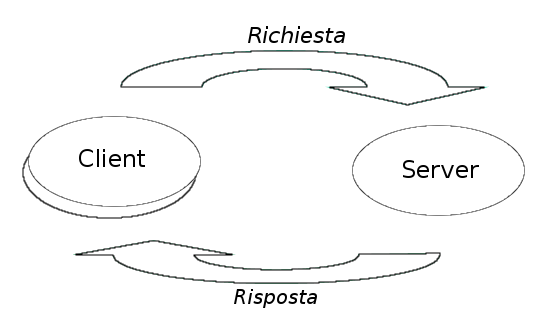
Le interazioni tra client e server sono sempre del tipo richiesta/risposta: il client invia un messaggio di richiesta al server, il quale esegue il servizio richiesto ed invia al client un messaggio di risposta, che varia in base al servizio richiesto.
Il Web: HTTP e URL
Il Web può essere pensato come un insieme di client e di server che interagiscono tra di loro, utilizzando il protocollo HTTP come linguaggio comune. Comunemente il Web viene visualizzato attraverso un programma client dotato di interfaccia grafica, detto browser. Esempi noti di browser sono Google Chrome, Firefox o Safari.
All’interno del Web, ogni oggetto (ad esempio un file musicale o un’immagine) viene identificato univocamente da un URL (Uniform Resource Locator), una sequenza di caratteri che fornisce informazioni su come localizzare quell’oggetto. L'esempio più semplice di URL è il seguente:
http://www.google.it/index.html
Questo URL è formato da tre parti:
httpè il tipo di protocollo utilizzato per scambiare le informazioni;www.google.itè il nome del dominio, che identifica l'indirizzo del sito web;index.htmlè il nome del file richiesto (in questo caso una pagina HTML).
Quando viene digitato sul browser questo particolare URL, quello che succede è che il browser apre una connessione verso il server Web che si trova in esecuzione su una macchina il cui indirizzo IP corrisponde al nome di dominio www.google.it. Tale connessione è tipicamente una connessione TCP, tramite cui il browser riceve e visualizza in maniera immediata il file di nome index.html.
Ecco, ora a voler essere precisi, gli URL possono anche essere più complicati dell'esempio fatto. Ad esempio potrebbero essere genericamente così:
protocollo://host[:porta]/percorso[?querystring][#fragment]
In questa formulazione si evidenziano i parametri opzionali, mettendoli tra parentesi quadre. I campi hanno il seguente significato:
protocolloè il tipo di protocollo utilizzato per scambiare le informazioni (http, htttps, etc);hostè il server che vogliamo contattare, specificato come indirizzo IP o come nome di dominio;portaè il numero di porta su cui è in esecuzione il servizio di rete che interessa al client;percorsoè il pathname della risorsa che viene richiesta dal client;querystringè la stringa con cui il client invia al server dei parametri;fragmentè utilizzato principalmente nelle pagine Web per indicare una posione all'interno della pagina.
